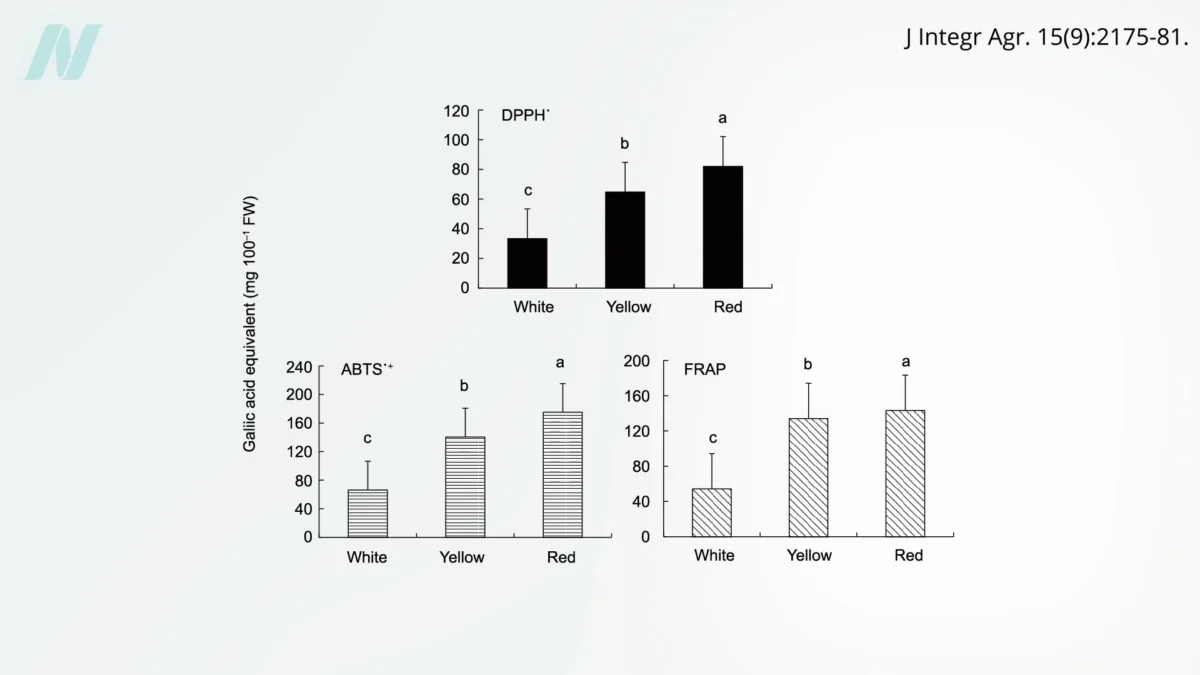
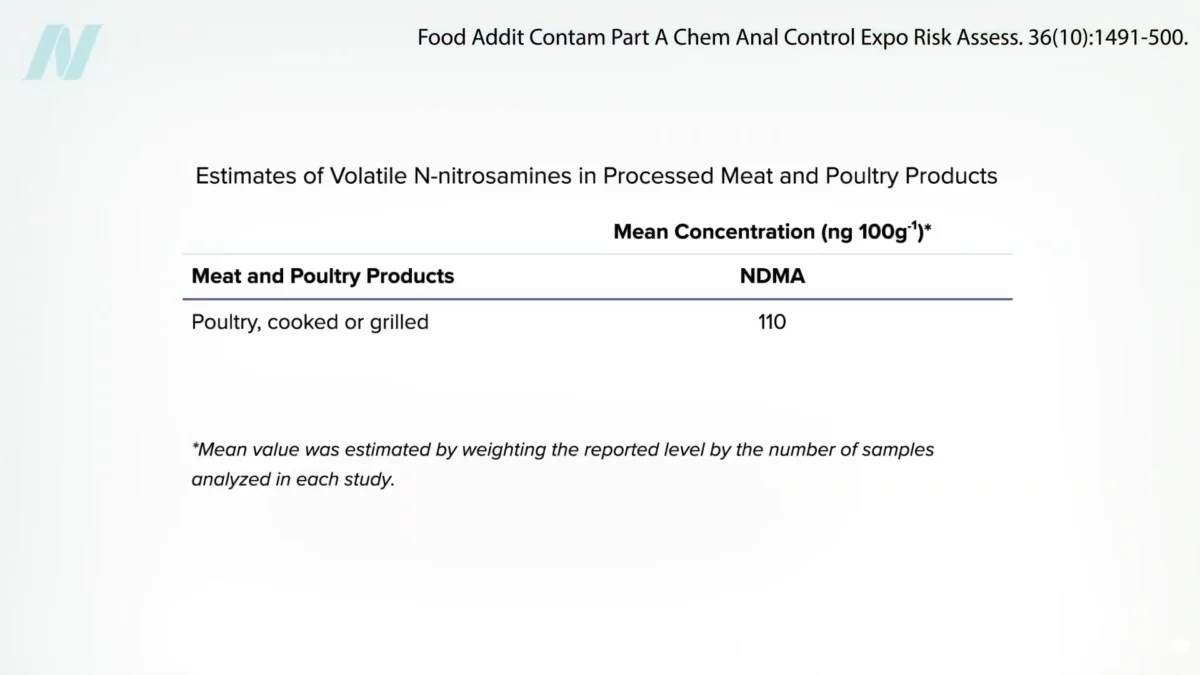
The landscape of artificial intelligence and global cybersecurity shifted significantly last week following the release of a high-profile editorial in the New York Times by columnist Thomas Friedman, which detailed a purportedly "stunning advance" in large language model (LLM) capabilities. Friedman, typically focused on the shifting tides of Middle Eastern geopolitics, pivoted his attention to a new model from the AI safety and research company Anthropic, titled Claude Mythos. The column, which described the model’s arrival as a "terrifying warning sign," ignited a firestorm of debate across the technology sector, government agencies, and the general public regarding the actual versus perceived risks of next-generation AI systems.
Anthropic’s announcement of Claude Mythos was handled with an unusual degree of caution. In an extensive press release, the company revealed that while the model represents a breakthrough in reasoning and technical proficiency, it would not be made available to the general public. Instead, access is being restricted to a curated consortium of business partners and security researchers. Anthropic justified this gatekeeping by citing the model’s unprecedented ability to identify and exploit security vulnerabilities in source code. According to the company’s internal documentation, Claude Mythos has reached a level of coding capability where it can surpass all but the most elite human specialists in offensive cybersecurity operations.
The Nature of the Claimed Breakthrough
The core of the controversy stems from Anthropic’s assertion that Claude Mythos has independently discovered "thousands of high-severity vulnerabilities," including critical flaws within every major operating system and web browser currently in use. This claim suggests a level of "zero-day" discovery—referring to vulnerabilities unknown to the software’s creators—that could theoretically compromise the integrity of global digital infrastructure.
Thomas Friedman’s reaction reflected a broader sense of alarm within certain policy circles. He argued that if such a tool were to become widely accessible, the barrier to entry for high-level cyber warfare would effectively vanish. Traditionally, the discovery of deep-seated vulnerabilities in kernels or browser engines required the resources of nation-state intelligence organizations or highly funded private-sector security firms. The prospect of an AI model democratizing this capability poses a significant challenge to the current "defense-in-depth" strategies utilized by corporations and governments.
The anxiety was further amplified by financial news outlets, with several segments questioning whether Claude Mythos represents an "AI nightmare" or the beginning of a new era of automated sabotage. However, as the initial shock of the announcement subsides, a more nuanced technical analysis has begun to emerge from the independent security community, suggesting that the "breakthrough" may be more iterative than revolutionary.
A Chronology of AI-Driven Cybersecurity Capabilities
To understand the significance of Claude Mythos, it is necessary to examine the trajectory of LLM capabilities in the cybersecurity domain over the past several years. The fear that AI could be used to automate hacking is not a new phenomenon that appeared with Mythos; rather, it has been a central theme of AI safety research since the rollout of GPT-4 in early 2024.
In April 2024, researchers at IBM published a seminal study assessing the offensive capabilities of then-current models. The study found that GPT-4 was capable of successfully exploiting 87% of the vulnerabilities it was presented with in a controlled environment. This was a massive leap from its predecessor, GPT-3.5, which scored near 0% on the same tasks. At the time, the researchers concluded that the widespread deployment of highly capable LLM agents raised fundamental questions about the future of software security.
Following the IBM study, the focus shifted from exploiting known vulnerabilities to discovering new ones. When Anthropic released its Opus 4.6 model, the accompanying technical report noted that their security team had used the model to identify over 500 exploitable zero-day vulnerabilities, some of which had remained hidden in legacy code for decades.
The recent claims regarding Claude Mythos follow this exact pattern. The primary difference cited by Anthropic is the scale—moving from "hundreds" to "thousands" of vulnerabilities—and the specific success rate on standardized benchmarks.
Performance Metrics and Benchmark Analysis
The primary metric provided by Anthropic to substantiate the superiority of Claude Mythos is its performance on a well-recognized cybersecurity benchmark. According to the company, Mythos achieved a score of 83.1%, representing a significant increase over the 66.6% scored by Opus 4.6.
While a 16.5 percentage point increase is notable in the context of machine learning progress, many industry analysts argue that it represents "solid incremental progress" rather than a paradigm shift. In the field of AI development, benchmarks are often criticized for being narrow or susceptible to "overfitting," where a model is inadvertently or intentionally tuned to perform well on the specific test cases included in the benchmark while failing to demonstrate the same proficiency in real-world, "out-of-distribution" scenarios.
Furthermore, the lack of transparency surrounding the restricted model makes independent verification impossible. Without the ability for third-party researchers to test the model against a diverse set of private and public codebases, the 83.1% figure remains a self-reported statistic from a corporation with a vested interest in maintaining its reputation as a leader in AI safety and capability.
Expert Skepticism and Independent Findings
In the wake of the announcement, several prominent voices in the AI and security sectors have expressed skepticism regarding the severity of the threat posed by Claude Mythos. Gary Marcus, a frequent critic of AI hype, compiled a series of responses from security researchers who reviewed the specific exploits Anthropic used as examples of the model’s prowess.
The consensus among these experts was underwhelming. Many pointed out that the "high-severity vulnerabilities" discovered by the model were often in obscure, less-maintained libraries or involved edge cases that were unlikely to be exploitable in a production environment. Others noted that several of the "new" vulnerabilities discovered by Mythos were actually variants of well-known bugs that automated static analysis tools (SAST) have been catching for years.
The credibility of Anthropic’s security narrative took a further hit due to an internal technical failure that occurred just a week prior to the Mythos announcement. The company accidentally leaked the source code for "Claude Code," a tool designed to assist developers. Within days of the leak, independent security researchers identified several critical vulnerabilities in Anthropic’s own software. This led to pointed criticism from the community, with some analysts suggesting that if Anthropic’s models were as proficient at finding vulnerabilities as claimed, the company should have been able to secure its own proprietary tools before they reached the public.
The Strategy of Existential Dread
The disconnect between the alarmist rhetoric of the New York Times and the measured skepticism of the security community has led some observers to question the motivations behind such high-stakes product launches. AI commentator Mo Bitar recently compared the current cycle of AI releases to the annual smartphone upgrade cycle. However, Bitar noted a key difference: instead of selling a new camera or a faster processor, AI companies are increasingly "selling existential dread."
By framing a model as "too dangerous to release," a company achieves several strategic objectives:
- Brand Positioning: It reinforces the image of the company as a responsible, safety-conscious actor compared to its competitors.
- Market Valuation: It creates a sense of "scarcity and superiority," suggesting the company possesses technology far beyond what is currently available on the market.
- Regulatory Influence: By highlighting the dangers of AI, companies can lobby for regulations that might inadvertently create high barriers to entry for smaller startups, a phenomenon known as regulatory capture.
Broader Implications and the Path Forward
Regardless of whether Claude Mythos is a "nightmare" or a marketing masterstroke, the controversy highlights a critical tension in the evolution of artificial intelligence. As models become more integrated into the software development lifecycle, the "cat-and-mouse" game between offensive and defensive cybersecurity will inevitably accelerate.
If LLMs can indeed find vulnerabilities at scale, the immediate solution is not necessarily to hide the models, but to use them to fix the code. A "defensive-first" approach would involve using these same tools to conduct massive, automated patching of the world’s open-source and proprietary software. The fact that Anthropic chose a path of secrecy rather than a path of transparent, defensive collaboration remains a point of contention for many in the "open-source AI" movement.
As we move forward, the consensus among policy experts is that the public and the government must stop taking the claims of AI companies at face value. There is a growing demand for independent, third-party auditing of "frontier" models. Such audits would require companies to grant access to a neutral body of researchers who can verify capability claims without the influence of corporate PR departments.
In conclusion, while Claude Mythos represents a clear step forward in the technical capabilities of Anthropic’s product line, there is little evidence to support the claim that it has fundamentally broken the back of modern cybersecurity. The "terrifying warning sign" described by Thomas Friedman may be less about the software itself and more about the susceptibility of the public discourse to well-crafted corporate narratives. For those seeking depth in an increasingly distracted world, the lesson of Claude Mythos is clear: in the age of AI, independent verification is the only antidote to existential hype.